最近,小红书技术团队完成了一件前所未有的壮举: 一年内,把业界最大数据湖0故障迁上阿里云。
壮举的背后意味着风险和挑战。
作为中国头部互联网公司之一,小红书月活用户已过3亿,其数据湖存储了过去11年的所有原始数据,包括结构化、半结构化和非结构化数据。近年来,随着业务的高速增长,小红书在线处理数据的需求不断增加,同时离线处理所积累的历史问题,也提高了切换的难度。
为此,2023年11月,小红书共有1500人参与迁云项目——计划一年内,把小红书的数据湖搬上阿里云。
饶是如此,难度依旧超出想象。即便是业界体量最大的案例,也远小于小红书的本次迁移。
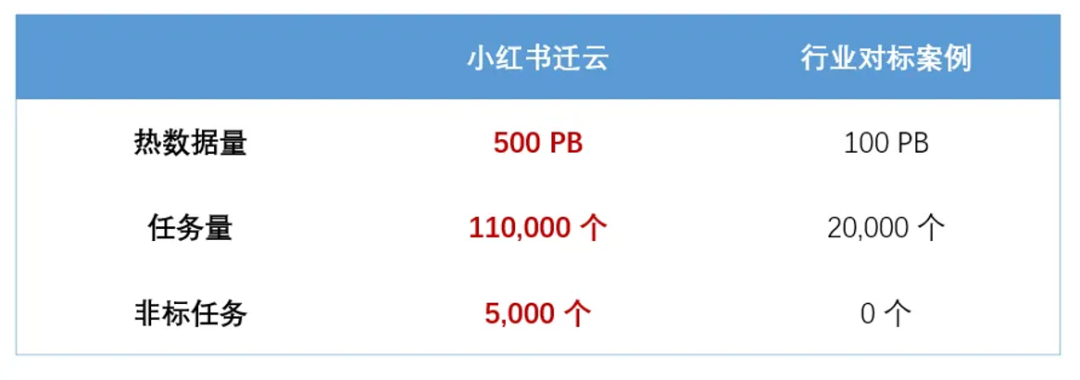
*注:任务=数据处理过程(如,数据出入数仓就需要通过任务进行调度)
// 拉着1500人一起开盲盒
2023年11月,项目组正式成立,在小红书内部出现了一种声音,觉得这是个「推着推着就会不了了之的事」。
不看好的理由,来自于沉重的历史包袱。
这是小红书历史上首次盘点公司数字资产,过去11年发展历程中积累了大量无主任务与不标准操作。即便前期做了取舍,仍需要大量治理。
即便压力重重,团队还是在立项文档的最后一行写下了4个字,「干就完了」。
首先要解决的还是标准问题。
过去的数据平台开发模式混乱,需要在迁移前把新的基础环境搭建好,切换到自研平台,统一开发标准。
其次根据标准进行治理。
大家把这一过程形容为「拉着1500人一起开盲盒,如果不打开就不知道里面有多千奇百怪」。
以下是几种典型:
· 引用自己写的「野生」代码
· 离线任务不按规范经过数仓,直接访问在线
· 源代码已丢失、流程已丢失
· 交接好几手,「跑很久没挂,就一直没管」
为此,小红书几大业务的负责人,把各自OKR的最重要一项列为迁云,开始为结果负责、推动问题解决。
数据平台与业务技术的配合也变得更加紧密。
// 如果项目失败,可能的原因是什么?
在迁云项目中,关键是「舍掉什么」以及「谁来拍板」,背后对应着两个「有限」:
1. 时间有限
量大,无法一次性全量迁移。
为此团队总结出了一套取舍的标准:「长期无人维护、访问,说明不重要」、「断掉后没有人举手,说明不重要」。同时在测试环境中频繁演练、迭代。
2. 准确度有限
需要和项目验收方提前达成共识。
算法类:算法数据工程负责人验收。
报表类:由数据分析负责人验收。懂数据,更易拉齐与收敛。
子城是小红书迁云项目负责人,在他看来,这一次会议很关键,「跟算法数据工程负责人和DI负责人拉齐标准、一起排查验收,大大降低了验收环节的难度」。
// 到底还有多少问题需要解决?
完成治理后,项目在2024年5月正式进入双跑阶段。作为切换到正式环境前最后的测试,是稳定性最大的保障。需要把数据拷贝到阿里云,两边同时跑数,验证正确性与及时性。
这一阶段,需要解决的问题数不胜数。
类似「蜘蛛网」,数据从入仓到出仓,需要经过一条漫长的链路,通过各种任务进行处理,也在双跑中带来了三个问题:
一、在其中的网状结构中,下游数据会受到上游影响,一个小小的错误就会带来很大的偏差,难以归因;
二、算法具有随机性,如果不跑就不知道会有什么问题;
三、现有的任务仍随着业务的发展在快速新增,导致每次链路都会有所不同。
每周都会平均新增500多个问题,推进起来十分缓慢。问题的积累最终造成了延期。问题很严峻,项目组开始了全面的复盘。
首先要做的仍然是顶层的取舍。
任务多,时间有限,则必须先解决最重要的问题。最终确定:高风险任务>高优任务>普通任务的判断逻辑。
这一原则让项目团队更明确需要重点解决的问题。
// 保障割接无故障
灵活的调整之下,进度很快被追回。
团队士气高涨,开始自发给自己提出了更高要求:把准确度从90%提高到99%,进度上要求自己提前1个月完成任务,同时确保P2及以上的故障小于等于3个。
8月,项目结束双跑,进入割接阶段。需要断掉跑数过程,并在新云上观察结果。一旦产生故障,不但影响用户体验,还会带来直接的资产损失。最主要的目标也因此从速度变成了质量。
正式双跑定在了9月,一周时间,所有人在会议室完成线下割接,一旦出现问题,就当下立刻解决。
阿里云团队也全程在现场保障。让他们印象最深的是,「小红书技术团队反应速度很快,出现了问题,第二天就能闭环处理」。
在全力保障之下,团队顺利完成了割接,没有发生任何一个P2及以上故障。
// 客户成功才是最大的价值
2024年11月,小红书迁云项目正式宣告结束。在没有故障的情况下,迁移数据500PB,任务11万。参与人数1500人,涉及部门40多个。
迁移至阿里云上后,数据湖可通过多个OSS Bucket支持纳入统一资源池,实现多个Bucket共享资源池内的OSS吞吐及QPS能力。这样的流控能力在面向小红书复杂业务场景,可灵活调配资源,高效利用吞吐性能,降低不同业务租户间的互相影响。
阿里云原生HDFS+DLA元数据可实现无缝对接Hadoop EMR体系,支持元数据线性扩展能力,轻松应对小红书数百PB数据下的元数据线性增长。
在结项会议上,阿里云智能集团资深副总裁、公共云事业部总裁刘伟光分享了一个小故事。
他翻到了多年前的一次会议记录。2021年的一次交流会议中,他和小红书中台技术负责人凯奇第一次谈到了数据湖迁云的可能,三年后终于一起见证了小红书的成长,与迁云项目的落地。
刘伟光说:「三年中小红书发生了巨大的变化,到今天变成了一个国民级的APP,作为云厂商,客户的成功也是我们最高兴的事」。
对于小红书迁云项目成员而言,他们也因为这个项目创造了历史:第一次系统性盘点了小红书十多年的数字资产,第一次参与千人以上、涉及公司所有产品的项目,共同完成了业界最大体量的迁云项目。
这些第一次为大家带来了「信心」的提升。
有人说,「做完这个项目,再做任何事都不会怵了」。